SVM回归预测算法 – 基于支持向量机的回归分析【Python】
最后更新于:2025-10-29 00:57:01
最后更新于:2025-10-27 18:00:00
一、代码运行环境
- Python: Python 3.6+
- 依赖库:
numpy,scikit-learn,matplotlib - 可以通过
pip install -r requirements.txt命令安装所有依赖。
二、程序介绍
本代码提供了一个完整的基于Python的SVM回归预测解决方案,适用于各类回归问题。
程序文件结构
SVM_Regression/
│
├── demoSVM_Regression.py // 主运行脚本
├── FunRegSVM.py // 核心SVM回归函数
├── housing.txt // 演示数据集(波士顿房价)
├── requirements.txt // Python依赖库列表
└── figure/ // 存放结果图片的文件夹
├── 图1.png
├── 图2.png
├── 图3.png
└── 图4.png文件说明
1. demoSVM_Regression.py
- 说明:主运行脚本,演示了如何调用
FunRegSVM函数。包含了数据加载、参数配置和函数调用等完整流程。 - 运行结果:
- 程序会生成4张分析图表,保存在
figure文件夹下。 - 图1:训练集拟合效果
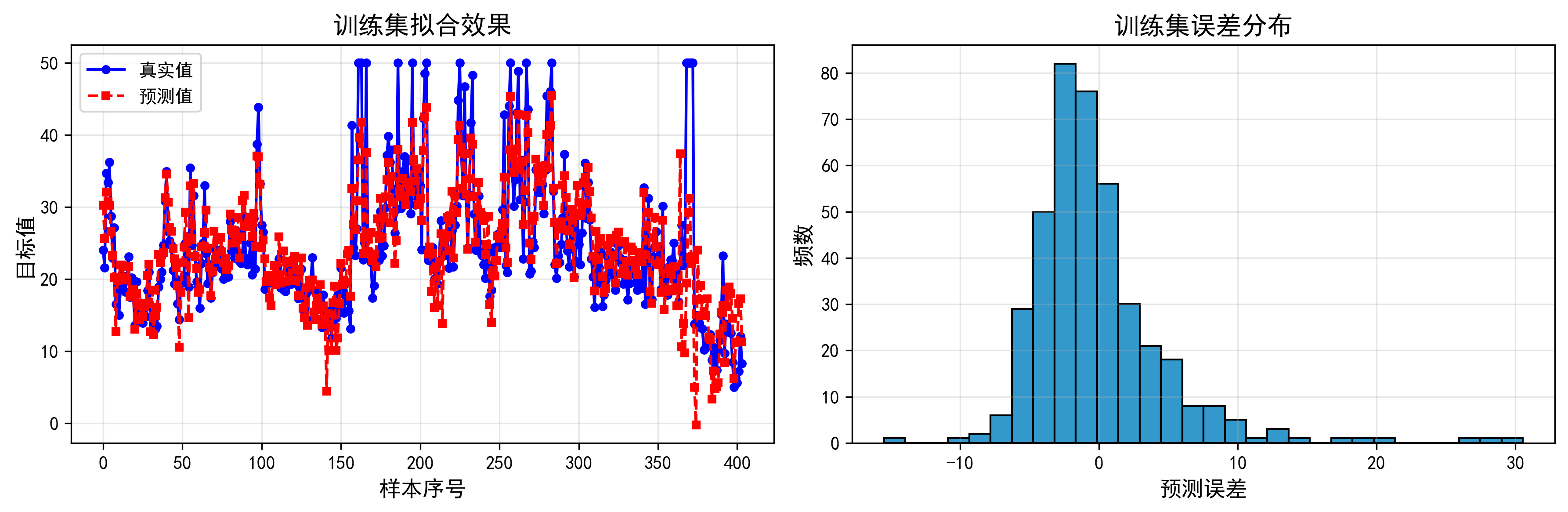
- 图2:测试集预测效果
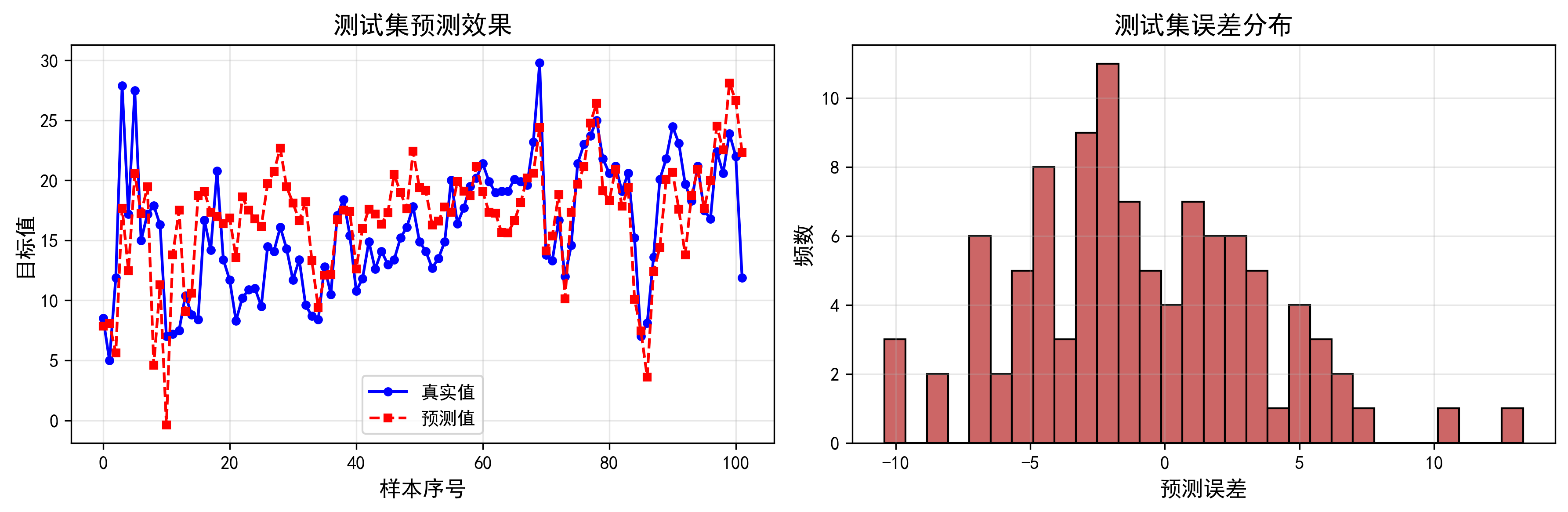
- 图3:真实值与预测值对比
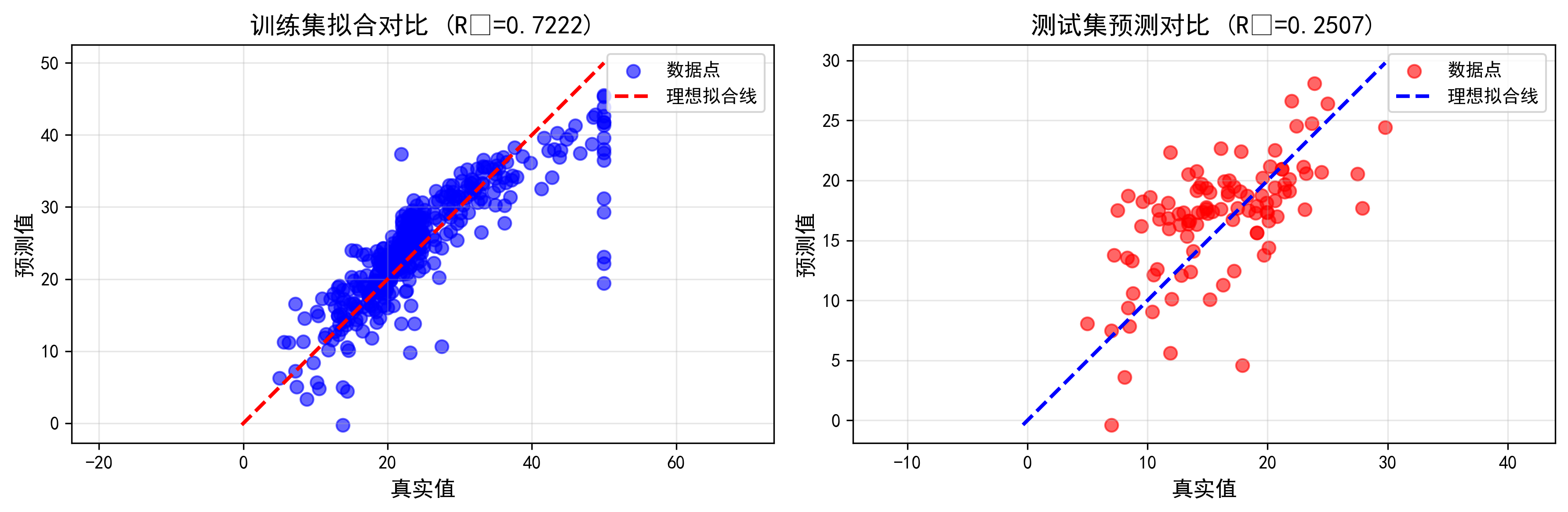
- 图4:性能指标对比
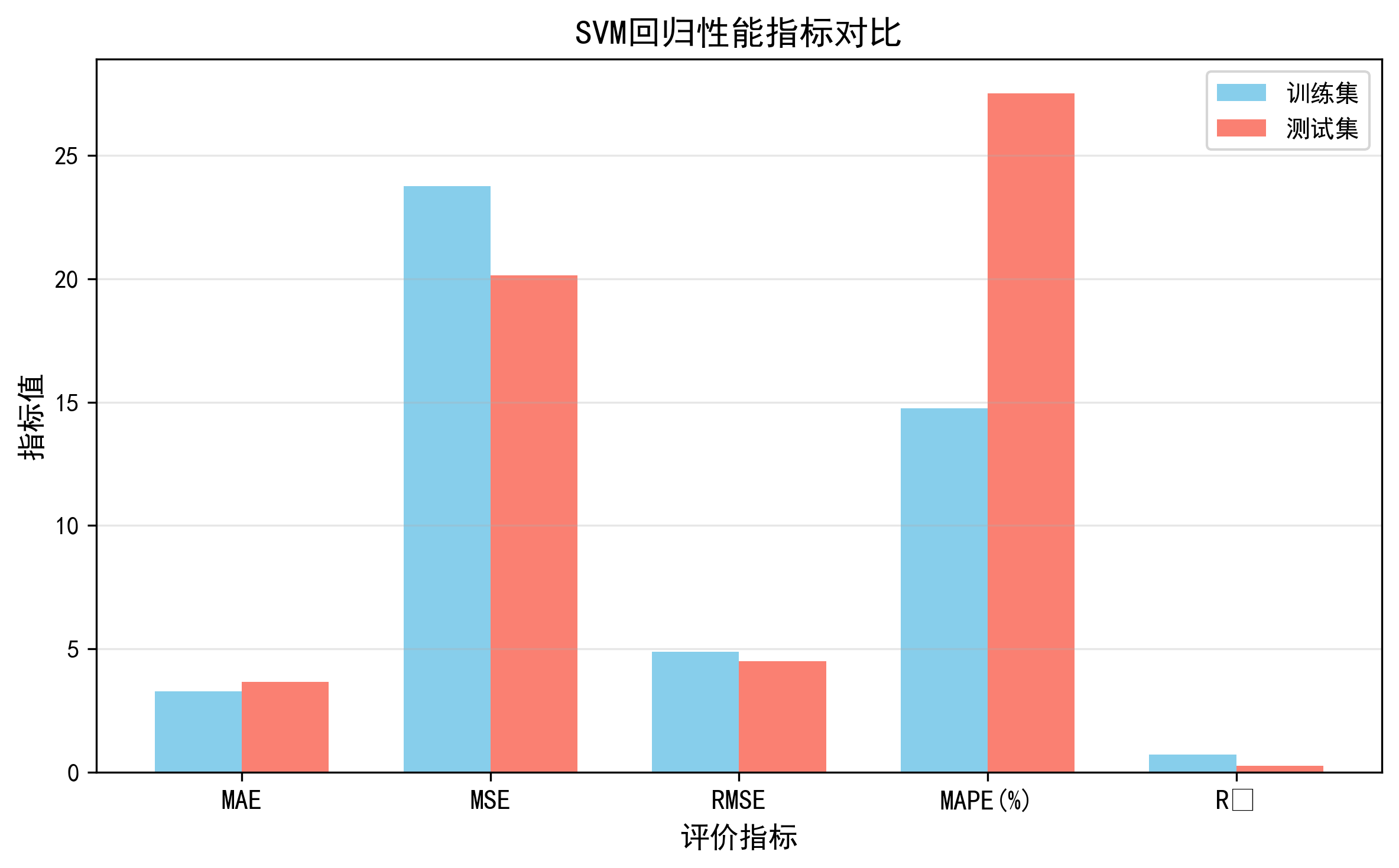
2. FunRegSVM.py
- 说明:封装了SVM回归的核心功能,包括数据归一化、模型训练、预测评估和结果可视化。
- 函数定义及参数解释:
def FunRegSVM(X: np.ndarray, Y: np.ndarray, options: Optional[Dict] = None) -> Tuple[np.ndarray, np.ndarray, Dict]:
"""
SVM回归预测函数
Parameters:
-----------
X : np.ndarray
输入特征矩阵 [n_samples, n_features]
Y : np.ndarray
输出目标向量 [n_samples,]
options : Dict, optional
参数设置字典:
- rTrain: 训练集比例 (默认0.7)
- kernel: 核函数 'linear'|'rbf'|'poly' (默认'rbf')
- C: 惩罚系数 (默认1.0)
- epsilon: 容忍带宽度ε (默认0.1)
- gamma: 核函数系数 (默认'scale')
- figflag: 是否绘图 (默认True)
Returns:
--------
foreData : np.ndarray
测试集预测结果
foreDataTrain : np.ndarray
训练集拟合结果
info : Dict
包含模型、评价指标等的详细信息
"""3. requirements.txt
- 说明:包含了运行此代码所需的所有Python第三方库及其版本,方便用户快速配置环境。
三、快速开始
1. 配置环境
- 打开终端或命令行窗口,进入代码所在目录。
- 运行
pip install -r requirements.txt来安装所有必要的依赖库。
2. 运行测试脚本
- 在终端中运行命令
python demoSVM_Regression.py。 - 程序将自动执行训练和预测,并在完成后显示结果图,同时在
figure文件夹中保存图片。
3. 修改/导入数据
- 打开
demoSVM_Regression.py文件,修改数据加载部分:
# 将'your_data.txt'替换为您的数据文件名
data = np.loadtxt('your_data.txt')
X = data[:, :-1] # 假设除最后一列外都是特征
Y = data[:, -1] # 假设最后一列是目标值- 请确保数据格式为纯文本,可以使用
numpy.loadtxt正确加载。 - 关于更详细的数据导入方法,如Excel、CSV、.mat等,可以参考这篇详细教程:Python的数据导入
4. 调整模型参数
- 在
demoSVM_Regression.py中,可以直接修改options字典来调整模型参数:
options = {
'rTrain': 0.8, # 训练集比例
'kernel': 'rbf', # 核函数: 'linear', 'poly', 'sigmoid'
'C': 10.0, # 惩罚系数
'epsilon': 0.1, # 容忍带宽度ε
'gamma': 0.01, # 核函数系数
}参数调优建议: 1. 从默认参数开始,重点关注C和gamma(当kernel为rbf时)。 2. 如果模型过拟合,尝试减小C或gamma。 3. 如果模型欠拟合,尝试增大C或gamma。 4. 使用scikit-learn的GridSearchCV进行系统的参数搜索是找到最优参数的最佳实践。
四、关于完整版与公开版代码
> 代码分为完整版和公开版(试用版),以满足不同用户的需求。
| 功能 | 完整版 | 公开版 |
| 数据导入、参数设置 | √ | √ |
| 软件全部源码 | √ | × |
| 核心函数源码 | 完整可见 | 加密(.pyd文件) |
| 数据样本数限制 | 无限制 | 最大100个样本 |
| 画图水印 | 无水印 | 有水印标识 |
| 视频教程 | √ | × |
| 技术支持 | 提供技术支持 | 无技术支持 |
| 代码注释 | 详细注释 | 部分注释 |
—
📥 五、获取公开版程序
SVM回归预测_Python试用版
💎 六、获取完整版程序
点击下面”立即支付“按钮,付款后获取完整版代码下载链接和售后联系方式~付款完成后刷新一下本页面即可看到下载链接。
(注意:支付跳转失败的话,请使用浏览器打开本页面)
七、完整版代码重要更新
- 2025-10-27: 完成初版代码
- 实现基于scikit-learn SVR的回归预测
- 支持多种核函数
- 提供完整的性能评估指标
- 生成4种可视化结果
- 自动保存图片到figure文件夹
八、常见问题
Q1: pip install失败怎么办?
A: 1. 检查网络连接,尝试更换pip镜像源:pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple 2. 确保您的Python和pip是最新版本。 3. 部分库(如numpy)编译时可能需要C++环境,可以尝试从官网下载预编译的wheel文件进行安装。
Q2: 预测结果R²很低或为负数?
A: 1. 数据问题:检查输入数据是否存在大量噪声、异常值,或者特征与目标值之间根本没有强相关性。 2. 参数问题:C和gamma参数非常敏感。过大或过小都可能导致模型性能急剧下降。强烈建议使用网格搜索调优。 3. 归一化问题:代码默认进行归一化。如果您的数据已经归一化,请设置options['mapflag'] = False。
Q3: 如何保存训练好的模型?
A: 在demoSVM_Regression.py运行后,模型保存在info['model']中。推荐使用joblib库:
import joblib
# ...运行FunRegSVM之后...
# 保存模型
joblib.dump(info['model'], 'my_svm_model.pkl')
# 同时保存归一化工具
joblib.dump(info['scalerX'], 'my_scaler_x.pkl')
joblib.dump(info['scalerY'], 'my_scaler_y.pkl')Q4: 如何用训练好的模型预测新数据?
import joblib
import numpy as np
# 加载模型和归一化工具
loaded_model = joblib.load('my_svm_model.pkl')
scaler_x = joblib.load('my_scaler_x.pkl')
scaler_y = joblib.load('my_scaler_y.pkl')
# 假设newData是新的特征数据 (numpy array)
# 使用加载的scalerX对新数据进行归一化
newData_scaled = scaler_x.transform(newData)
# 预测
predictions_scaled = loaded_model.predict(newData_scaled)
# 使用加载的scalerY进行反归一化
final_predictions = scaler_y.inverse_transform(predictions_scaled.reshape(-1, 1))
print(final_predictions)A: 加载模型和归一化工具,然后对新数据进行预测:
Q5: 如何引用本代码?
A: 如果在论文或报告中使用了本代码,建议注明:
代码来源:Mr.看海,SVM回归预测算法Python实现
网站:www.khsci.com/docs