SVM多分类算法 – 基于支持向量机的多类别分类【Python】
最后更新于:2025-10-12 00:15:02
一、代码运行环境
- Python: Python 3.8及以上版本
- 依赖库:
numpy >= 1.21.0– 数值计算库pandas >= 1.3.0– 数据处理库matplotlib >= 3.4.0– 数据可视化库scikit-learn >= 1.0.0– 机器学习库
二、程序介绍
程序文件结构
SVM_Multiclass_Classification/
├── demoSVMMultiClass.py # 演示脚本
├── FunSVMMultiClass.py # 核心函数
├── iris.csv # 鸢尾花数据集
├── requirements.txt # 依赖库列表
├── 代码说明.txt # 代码说明文档
└── figure/ # 结果图片文件夹
├── 图1_混淆矩阵.png
├── 图2_分类对比.png
├── 图3_性能指标.png
└── 图4_数据分布.png文件说明
1. demoSVMMultiClass.py
- 说明:SVM多分类算法的演示脚本文件,是核心函数
FunSVMMultiClass的测试文件,可以直接运行。 - 功能:加载鸢尾花数据集,设置算法参数,调用核心函数进行多分类训练和测试,输出性能指标并生成可视化结果。
- 运行结果:
命令行输出示例:
开始加载数据...
数据加载完成!
数据集大小:150个样本,4个特征
===== SVM多分类算法 =====
训练集样本数: 105
测试集样本数: 45
类别数量: 3
===== 分类结果 =====
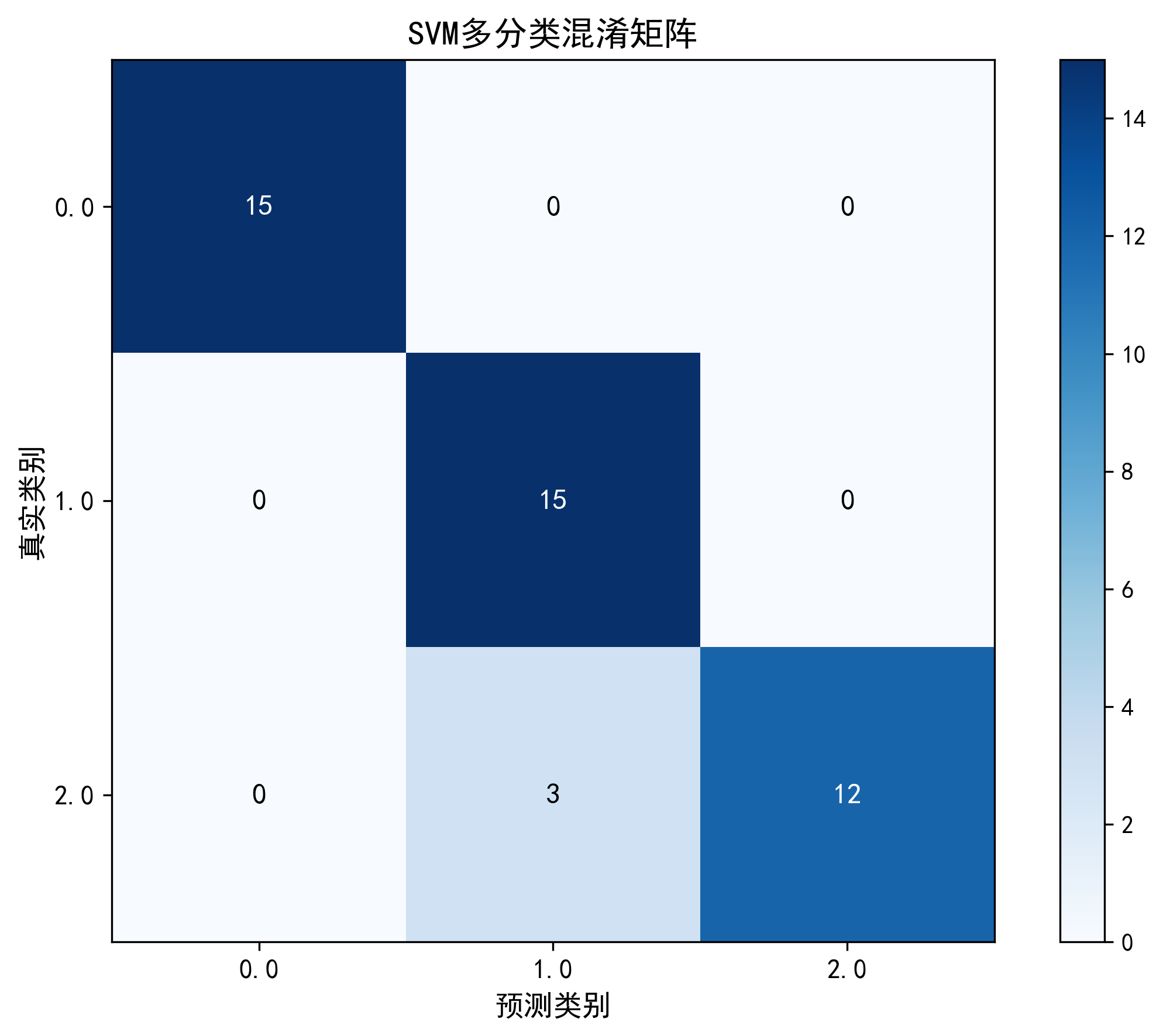
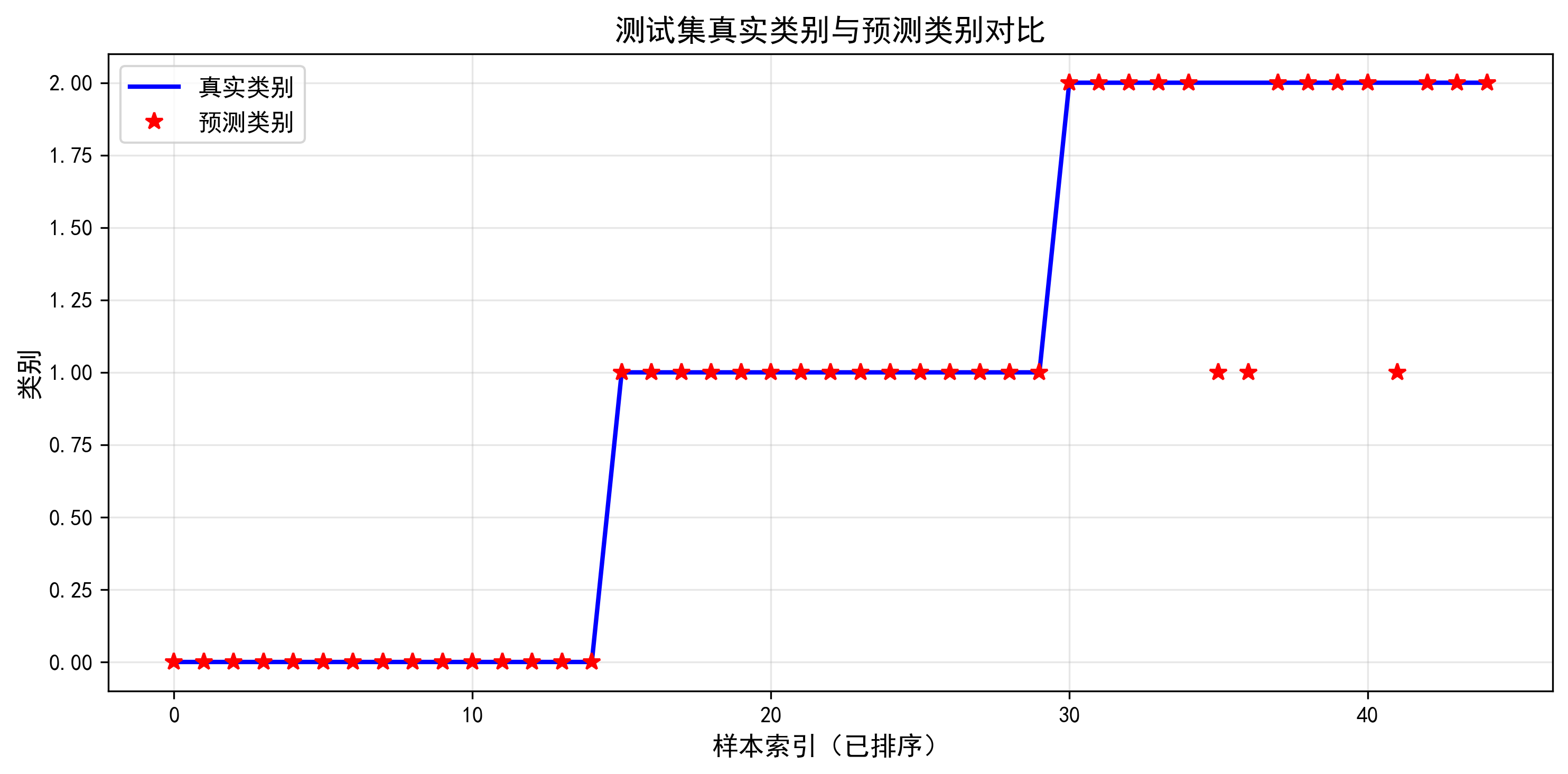
测试集准确率: 100.00%
精确率: 100.00%
召回率: 100.00%
F1分数: 100.00%
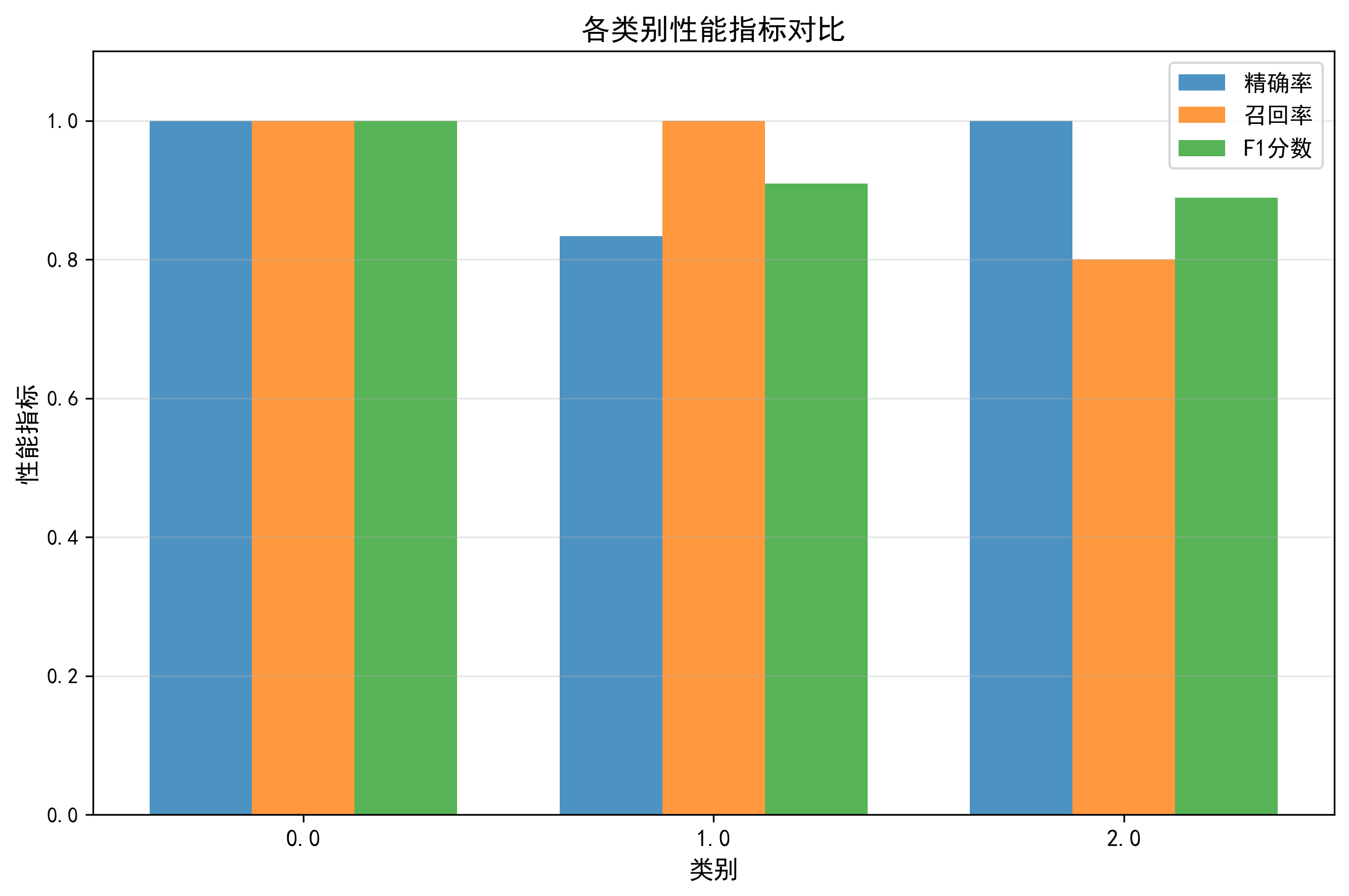
各类别性能指标:
类别 Iris-setosa: 精确率=100.00%, 召回率=100.00%, F1=100.00%
类别 Iris-versicolor: 精确率=100.00%, 召回率=100.00%, F1=100.00%
类别 Iris-virginica: 精确率=100.00%, 召回率=100.00%, F1=100.00%
所有图片已保存到figure文件夹
演示完成!2. FunSVMMultiClass.py
- 说明:SVM多分类算法的核心函数,实现了完整的多类别分类流程。
- 功能:
- 支持多种核函数(线性核、RBF核、多项式核)
- 采用One-vs-Rest(OvR)策略进行多分类
- 自动数据标准化和训练集/测试集划分
- 完整的性能评估(准确率、精确率、召回率、F1分数)
- 生成5种可视化结果(混淆矩阵、分类对比、性能指标、数据分布、决策边界)
- 支持中文字体显示
- 所有图片自动保存到figure文件夹
- 函数定义及参数解释:
def FunSVMMultiClass(X: np.ndarray,
y: np.ndarray,
options: Optional[Dict[str, Any]] = None) -> Tuple[float, float, float, float, List[SVC], Dict[str, Any]]:
"""
SVM多分类算法函数
Parameters:
-----------
X : np.ndarray
特征数据,shape为(n_samples, n_features)
y : np.ndarray
标签数据,shape为(n_samples,)
options : Dict[str, Any], optional
参数设置字典,包含以下字段:
- test_size: 测试集比例,默认0.3(30%测试,70%训练)
- kernel: 核函数类型,'linear'|'rbf'|'poly',默认'rbf'
- C: 惩罚系数,默认1.0
- gamma: 核系数,默认'scale'
- degree: 多项式核函数阶数,默认3
- standardize: 是否标准化,默认True
- figflag: 是否绘图,默认True
- random_state: 随机种子,默认123456
Returns:
--------
accuracy : float
测试集准确率
recall : float
召回率(各类别平均)
precision : float
精确率(各类别平均)
f1 : float
F1分数(各类别平均)
models : List[SVC]
训练好的SVM模型
info : Dict[str, Any]
包含详细结果的字典
"""3. iris.csv
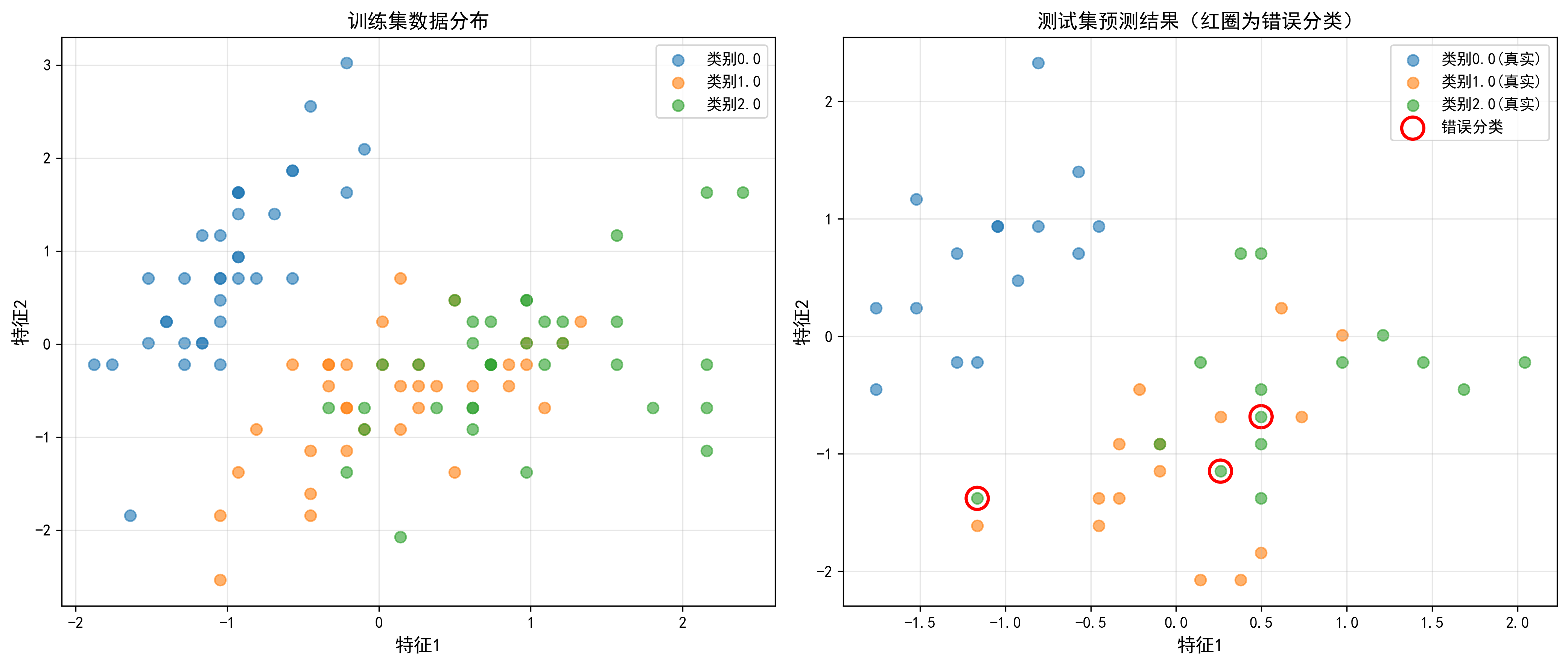
- 说明:经典的鸢尾花数据集,包含150个样本,4个特征(萼片长度、萼片宽度、花瓣长度、花瓣宽度),3个类别(Setosa、Versicolor、Virginica)。
- 用途:作为演示数据,展示SVM多分类算法的效果。
4. requirements.txt
- 说明:Python依赖库列表文件,列出了运行程序所需的所有第三方库及其版本要求。
- 用途:通过
pip install -r requirements.txt命令一键安装所有依赖。
5. 代码说明.txt
- 说明:详细的代码使用说明文档,包含环境要求、快速开始指南、主要功能介绍和参数说明。
三、快速开始
1. 环境配置
安装Python:
- 前往 Python官网 下载并安装 Python 3.8 或更高版本
- 安装时勾选 “Add Python to PATH”
安装依赖库:
方法一(推荐):使用 requirements.txt
# 打开命令行,切换到程序目录
cd path/to/SVM_Multiclass_Classification
# 安装所有依赖
pip install -r requirements.txt方法二:手动安装
pip install numpy pandas matplotlib scikit-learn验证安装:
python -c "import numpy, pandas, matplotlib, sklearn; print('依赖库安装成功!')"2. 运行测试脚本
步骤:
1. 打开命令行(Windows按Win+R输入cmd,Mac按Command+空格输入Terminal) 2. 切换到程序目录:
cd path/to/SVM_Multiclass_Classification3. 运行演示脚本:
python demoSVMMultiClass.py判断程序是否正常运行:
- 命令行输出完整的性能指标信息
- 自动弹出4个图形窗口,显示混淆矩阵、分类对比、性能指标和数据分布
- figure文件夹中自动生成4张PNG图片
- 没有报错信息
3. 修改仿真数据/导入数据
情况一:使用自己的仿真数据
1. 复制一个 demoSVMMultiClass.py 的文件副本(如 my_demo.py) 2. 在副本中修改数据导入部分(第16-21行):
# 1. 数据导入
# 使用自己的数据替换
X = your_feature_array # 替换为你的特征数据,shape=(n_samples, n_features)
y = your_label_array # 替换为你的标签数据,shape=(n_samples,)注意事项:
X必须是numpy数组或可转换为numpy数组的格式(如list、pandas DataFrame)y必须是一维数组或列表- 样本数必须与标签数量一致
- 特征数建议在2-100之间
情况二:使用真实采集的数据
从CSV文件导入(推荐):
import pandas as pd
import numpy as np
# 读取CSV文件
data = pd.read_csv('your_data.csv')
# 方法1:前几列是特征,最后一列是标签
X = data.iloc[:, :-1].values
y = data.iloc[:, -1].values
# 方法2:指定列名
X = data[['feature1', 'feature2', 'feature3']].values
y = data['label'].values从Excel文件导入:
import pandas as pd
# 读取Excel文件
data = pd.read_excel('your_data.xlsx', sheet_name='Sheet1')
X = data.iloc[:, :-1].values
y = data.iloc[:, -1].values从TXT文件导入:
import numpy as np
# 假设数据为空格或Tab分隔
data = np.loadtxt('your_data.txt')
X = data[:, :-1]
y = data[:, -1]
# 如果是逗号分隔
data = np.loadtxt('your_data.txt', delimiter=',')
X = data[:, :-1]
y = data[:, -1]从numpy数组导入:
import numpy as np
# 加载.npy文件
data = np.load('your_data.npy')
X = data[:, :-1]
y = data[:, -1]如果没有测试标签: 如果你的数据没有分开的测试集标签,需要修改代码:
1. 删除或注释掉性能评估相关代码 2. 只关注模型训练和预测结果 3. 可以使用 info['y_pred'] 获取预测结果
4. 调整算法参数(可选)
在 demoSVMMultiClass.py 的第28-37行可以调整算法参数:
# 设置参数
options = {
'test_size': 0.3, # 测试集比例(30%测试,70%训练)
# 可调整为0.2-0.4之间
'kernel': 'rbf', # 核函数类型
# 'linear':线性核,适合线性可分问题
# 'rbf':径向基核,适合大部分非线性问题(推荐)
# 'poly':多项式核,适合特定非线性问题
'C': 1.0, # 惩罚系数(越大对误分类的惩罚越大)
# 建议范围:0.1-100
'gamma': 'scale', # 核系数
# 'scale':自动计算(推荐)
# 'auto':自动计算
# 也可设置为具体数值,如0.1、1、10等
'degree': 3, # 多项式核阶数(仅poly核需要)
# 建议范围:2-5
'standardize': True, # 是否标准化数据(推荐True)
'figflag': True, # 是否绘图(True/False)
'random_state': 123456 # 随机种子(设置固定值保证结果可重复)
}参数调优建议:
1. 首先使用默认参数运行,观察结果 2. 如果准确率不理想,尝试调整核函数类型 3. 调整惩罚系数 C,通常在[0.1, 1, 10, 100]中选择 4. 如果使用RBF核,可以尝试不同的 gamma 值 5. 可以使用 sklearn.model_selection.GridSearchCV 进行自动参数搜索
使用GridSearchCV自动调参:
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
# 定义参数网格
param_grid = {
'C': [0.1, 1, 10, 100],
'gamma': ['scale', 'auto', 0.1, 1],
'kernel': ['rbf', 'linear']
}
# 创建网格搜索对象
grid_search = GridSearchCV(SVC(), param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)
# 输出最佳参数
print(f"最佳参数: {grid_search.best_params_}")
print(f"最佳准确率: {grid_search.best_score_:.4f}")5. 运行程序
完成以上修改后,在命令行运行:
python my_demo.py # 或者你修改后的脚本名称程序会自动完成数据加载、模型训练、预测和可视化等所有步骤。
四、关于完整版与公开版代码
> 代码分为完整版和公开版(试用版),以满足不同用户的需求。
| 功能 | 完整版 | 公开版 |
| 数据导入、参数设置 | √ | √ |
| 软件全部源码 | √ | × |
| 核心函数源码 | 完整可见 | 加密(.pyd文件) |
| 数据样本数限制 | 无限制 | 最大100个样本 |
| 所有核函数支持 | √ | √ |
| 完整可视化功能 | √ | √ |
| 画图水印 | 无水印 | 有水印标识 |
| 视频教程 | √ | × |
| 技术支持 | 提供技术支持 | 无技术支持 |
| 代码注释 | 详细注释 | 部分注释 |
| 跨平台支持 | Windows/Linux/Mac | 仅限编译平台 |
📥 五、获取公开版程序
注:公开版代码需使用MATLAB2022a及以上版本。
💎 六、获取完整版程序
点击下面”立即支付“按钮,付款后获取完整版代码下载链接和售后联系方式~付款完成后刷新一下本页面即可看到下载链接。
(注意:支付跳转失败的话,请使用浏览器打开本页面)
七、完整版代码重要更新
- 2025-01-10: 完成初版代码
- 实现基于SVM的多分类算法(Python版)
- 支持多种核函数(线性、RBF、多项式)
- 实现One-vs-Rest多分类策略
- 提供完整的性能评估指标
- 生成5种可视化结果
- 支持中文字体显示
- 自动保存图片到figure文件夹
- 完整的类型注解和文档字符串
八、常见问题
Q1: 运行程序时提示 “No module named ‘xxx'”?
A: 这是依赖库未安装的问题,请:
pip install -r requirements.txt或单独安装缺失的库:
pip install 库名Q2: 图片中文显示为方框?
A: 这是中文字体问题,可以:
1. 确保系统安装了中文字体(如SimHei、Microsoft YaHei) 2. 修改代码中的字体设置:
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows
# 或
plt.rcParams['font.sans-serif'] = ['Heiti TC'] # MacQ3: 运行时提示找不到文件?
A: 请确保:
1. 命令行当前目录就是程序所在目录(使用 cd 命令切换) 2. iris.csv 文件与Python脚本在同一目录 3. 使用 os.getcwd() 查看当前工作目录
Q4: 准确率很低怎么办?
A: 可以尝试:
1. 更换核函数类型(’linear’、’rbf’、’poly’) 2. 调整惩罚系数 C(尝试0.1、1、10、100) 3. 确保数据已标准化(standardize=True) 4. 增加训练集比例(如 test_size=0.2) 5. 使用GridSearchCV进行参数搜索 6. 检查数据质量和标签是否正确
Q5: 如何保存训练好的模型?
A: 使用 joblib 或 pickle:
import joblib
# 保存模型
joblib.dump(models, 'svm_models.pkl')
joblib.dump(info, 'model_info.pkl')
# 加载模型
models = joblib.load('svm_models.pkl')
info = joblib.load('model_info.pkl')Q6: 如何用训练好的模型预测新数据?
A:
# 假设 new_data 是新的特征数据
if info['standardize']:
# 使用训练时的标准化参数
new_data_std = (new_data - info['X_mean']) / info['X_std']
else:
new_data_std = new_data
# 预测
predictions = models[0].predict(new_data_std)
print(f"预测结果: {predictions}")Q7: 程序运行时间过长?
A:
1. 减少样本数量 2. 减少特征维度(使用PCA降维) 3. 使用线性核函数(kernel='linear',速度最快) 4. 减小 C 值 5. 使用更快的SVM实现(如LinearSVC)
Q8: 如何引用本代码?
A: 如果在论文或报告中使用了本代码,建议注明:
代码来源:Mr.看海,SVM多分类算法Python实现
网站:www.khsci.com/docs
使用的机器学习库:scikit-learn—
*如有其他问题,欢迎访问 www.khsci.com/docs 获取更多帮助信息。*